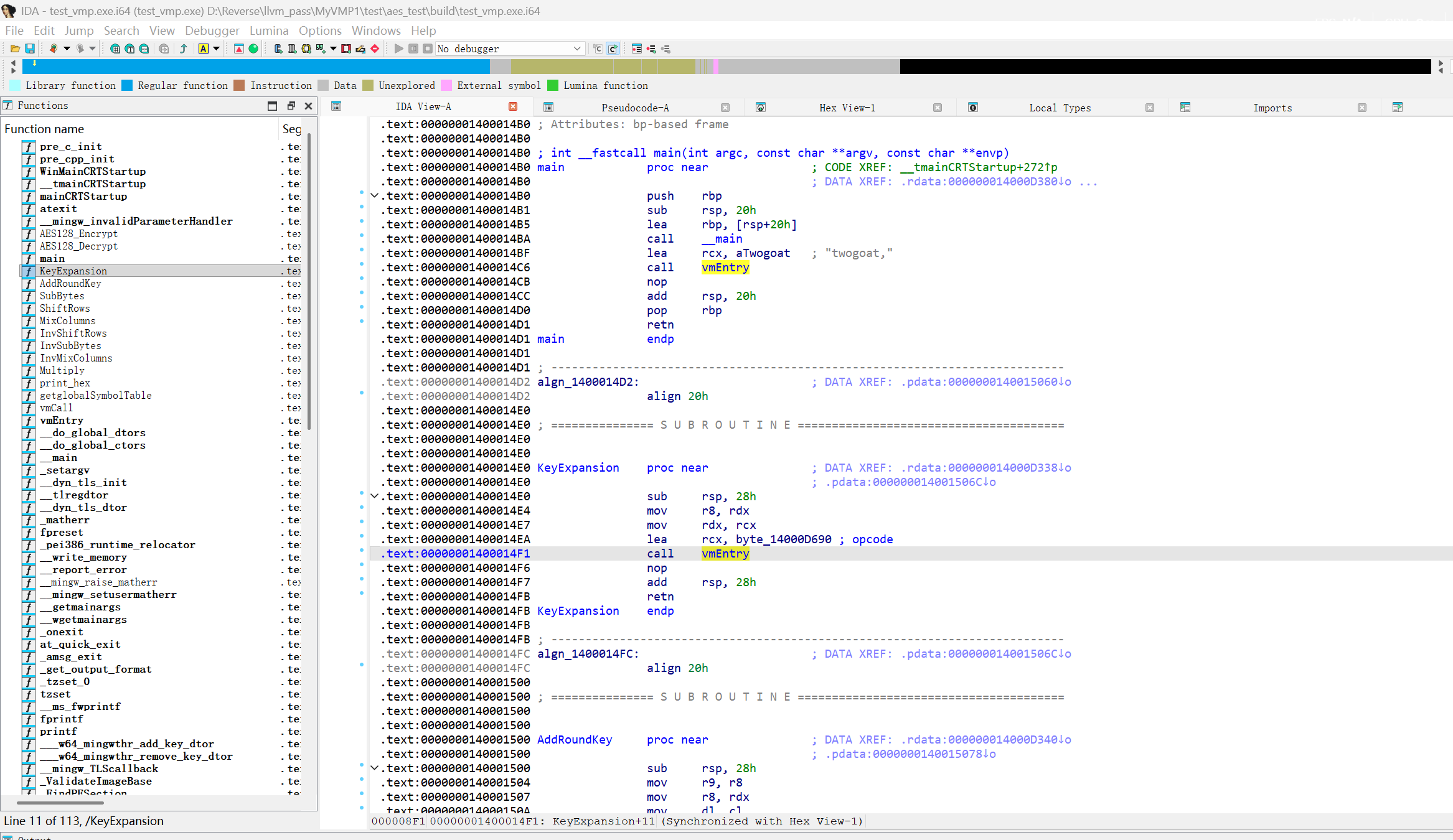
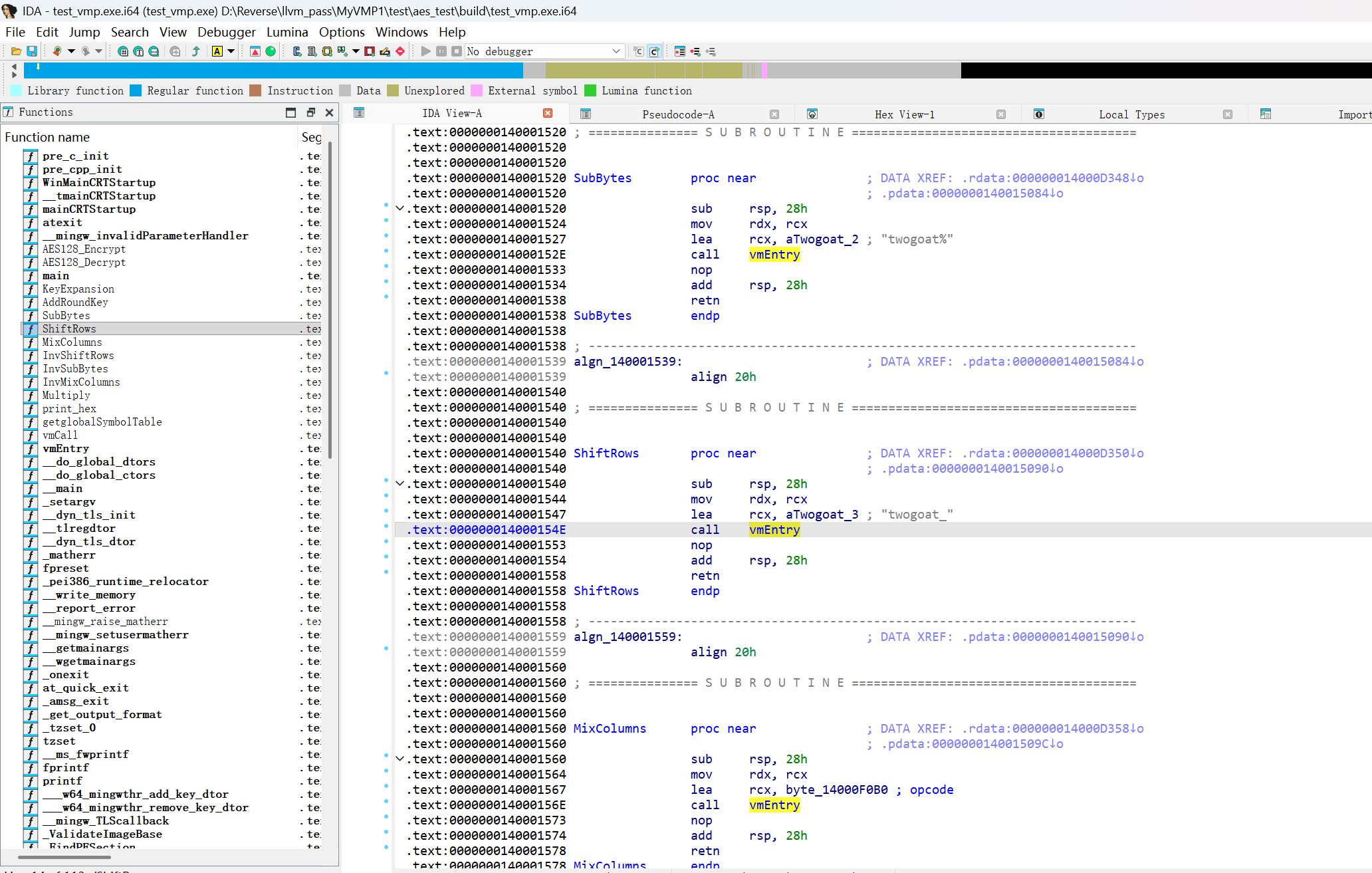
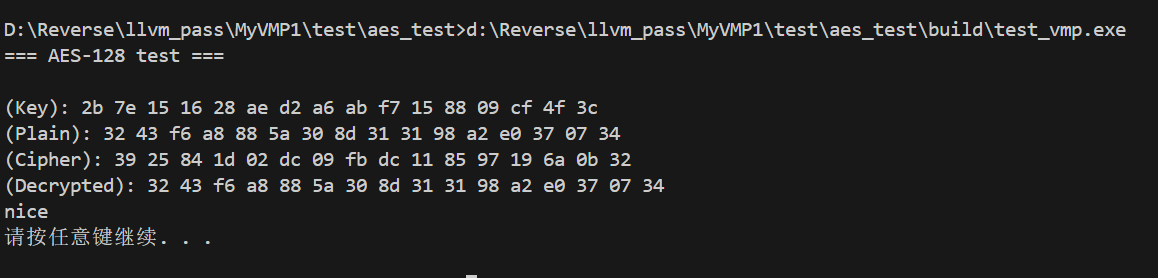
效果 添加声明的函数都走vmEntry
vmEntry添加CFF魔改后
运行结果正确
思路 过去无论是在CTF题目中,还是在真实的APP分析中,总能看到各种各样的VM。
就拿CTF来说,出题人要如何才能出一道VM题呢?
对我而言,如果我要在VM里塞入一个较复杂的算法,像TEA,但是在编写完VM框架后又不想过多思考如何编写bytecode,所以我选择先用标准c语言编译一份标准的TEA算法,然后对照着ida的反编译结果,去一条条对照着塞入汇编指令,最终写出来bytecode的结果大概是这样,不难看出是仿照x86架构的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 int32_t bytecode[] = { PUSH, NUM, dataIndex, PUSH, REG, EIP, PUSH, REG, EBP, MOV, REG_TO_REG, EBP, ESP, SUB, NUM_TO_REG, ESP, 0x50 , MOV, ADDR_TO_REG, EAX, EBP, INPUT, MOV, REG_TO_ADDR, EBP, -0x1C , EAX, MOV, ADDR_TO_REG, ECX, EBP, -0x1C , ADD, NUM_TO_REG, ECX, 0x1 , MOV, REG_TO_ADDR, EBP, -0x28 , ECX, //label1 0x29 MOV, ADDR_TO_REG, EDX, EBP, -0x1C , MOV, ADDR_TO_LOWREG, AL, EDX, 0 , ... }
但问题同样明显,虽然上面节省了自己过多思考去编写bytecode的时间,但实际在使用过程中,如果算法有那么一点小小改动,那么对于整个程序的执行流都是崩溃性的大调整,跳转指令的偏移全部要改,而且也得重新对照着汇编去增添bytecode,而且最主要的是函数调用,全局变量引用都十分麻烦。
在接触到llvm pass后,我的思路一下子豁然明朗。众所周知,llvm pass中可以通过各种api对LLVM IR进行处理,那么我们只需要解析对应声明Function的每一条Instruction,然后对翻译为我自己虚拟机框架的bytecode,然后修改函数入口为我自己vmEntry的入口,只传入对应的bytecode执行即可。
核心设计 代码结构 BytecodeReader 负责在字节码写入后,手动进行一次反汇编,方便debug
BytecodeWriter 负责字节码写入
CallSignatureAllocator 负责管理函数签名池,专门用于处理函数调用情况
FunctionWriter 是创建或者修改函数的地方,目前只有rewriteToVMStub(负责修改函数入口为传入bytecode地址原参数,并调用VmEntry),createVmCallFunction(为所有函数调用提供一个统一入口)和createGetglobalSymbolTableFuction(获取全局变量地址表)
Lowerer 是整个将LLVM IR翻译为自己虚拟机架构字节码的核心模块
SlotAllocator 负责给函数中出现的llvm::Value对象管理和分配寄存器槽索引
MyVMProtectPass 是注册Pass和入口点
TypeConverter 是llvm类型与字节VM类型之间转换的模块
runtime 中是VM的定义和主要代码,单独编译为bc字节码后再和主程序链接
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 include/ BytecodeReader.h BytecodeWriter.h CallSignatureAllocator.h FunctionWriter.h Lowerer.h SlotAllocator.h TypeConverter.h VMDefs.h src/ BytecodeReader.cpp BytecodeWriter.cpp CallSignatureAllocator.cpp FunctionWriter.cpp Lowerer.cpp MyVMProtectPass.cpp SlotAllocator.cpp TypeConverter.cpp runtime/ vm.c vm.h vm_opcodes.h
slot模型 / BinaryOperator运算指令 在LLVM中,存在着SSA特性,也就是每个变量只能被赋值一次
可以看到比如%114,在%115的Load指令后就没有再被引用了,但IR仍然不会给%114重新赋值
对于我们日常接触到的像X86或者ARM架构,寄存器的数量都是有限的。但现在对于每个LLVM IR函数作用域来说,变量数量都不定,有的可能只有10个,有的可能有几百个,因此我选择的是就按照出现的Value数量和size,去动态分配槽位。
这个Slot的概念,在我的虚拟机架构中非常关键,是运行起来的基础。
比如对于一个最简单的add函数
1 2 3 4 5 6 7 8 9 10 11 12 13 define dso_local dllexport i32 @add(i32 noundef %0 , i32 noundef %1 ) %3 = alloca i32, align 4 %4 = alloca i32, align 4 %5 = alloca i32, align 4 store i32 %0 , i32* %3 , align 4 store i32 %1 , i32* %4 , align 4 %6 = load i32, i32* %3 , align 4 %7 = load i32, i32* %4 , align 4 %8 = add nsw i32 %6 , %7 store i32 %8 , i32* %5 , align 4 %9 = load i32, i32* %5 , align 4 ret i32 %9 }
对于其中的ADD指令%8 = add nsw i32 %6, %7,当然在llvm pass中也可以统一为BinaryOperator
其中%8,%6,%7这些变量,在llvm中本质就是一个个llvm::Value对象
我的处理函数如下,通过先getOrCreateSlot,给各个Value分配一个槽索引,并添加该函数下槽的计数
然后再将运算类型和槽索引写入字节码中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 bool Lowerer::lowerBinaryOp (llvm::BinaryOperator& I) VM_SLOT dst = getOrCreateSlot (&I); VM_SLOT lhs = getOrCreateSlot (I.getOperand (0 )); VM_SLOT rhs = getOrCreateSlot (I.getOperand (1 )); writer.emitU8 (TypeConverter::toOPCODE_ID (I.getOpcode ())); writer.emitU8 (TypeConverter::toTYPE_ID (I.getType ())); writer.emitU16 (dst); writer.emitU16 (lhs); writer.emitU16 (rhs); return true ; }
在VM框架中,也依次把运算类型和槽索引读出来
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 case OP_ADD:case OP_SUB:case OP_MUL:case OP_SDIV:case OP_UDIV:case OP_SREM:case OP_UREM:case OP_AND:case OP_OR:case OP_XOR:case OP_SHL:case OP_LSHR:case OP_SHR: { TYPE_ID ty = read_u8(&vm); VM_SLOT dst = read_u16(&vm); VM_SLOT lhs = read_u16(&vm); VM_SLOT rhs = read_u16(&vm); switch (instType) { case OP_ADD: vmAdd(&vm, ty, dst, lhs, rhs); break ; case OP_SUB: vmSub(&vm, ty, dst, lhs, rhs); break ; case OP_MUL: vmMul(&vm, ty, dst, lhs, rhs); break ; case OP_SDIV: vmSdiv(&vm, ty, dst, lhs, rhs); break ; case OP_UDIV: vmUdiv(&vm, ty, dst, lhs, rhs); break ; case OP_SREM: vmSrem(&vm, ty, dst, lhs, rhs); break ; case OP_UREM: vmUrem(&vm, ty, dst, lhs, rhs); break ; case OP_AND: vmAnd(&vm, ty, dst, lhs, rhs); break ; case OP_OR: vmOr(&vm, ty, dst, lhs, rhs); break ; case OP_XOR: vmXor(&vm, ty, dst, lhs, rhs); break ; case OP_SHL: vmShl(&vm, ty, dst, lhs, rhs); break ; case OP_LSHR: vmLshr(&vm, ty, dst, lhs, rhs); break ; case OP_SHR: vmShr(&vm, ty, dst, lhs, rhs); break ; default : break ; } break ; }
然后直接利用索引,根据类型对分配的槽进行操作,实现了寄存器运算
1 2 3 4 5 6 7 8 9 static inline void vmAdd (VMState* vm, TYPE_ID ty, VM_SLOT dst, VM_SLOT lhs, VM_SLOT rhs) { switch (ty) { case TY_I8: vm->slots[dst] = (uint8_t )(vm->slots[lhs] + vm->slots[rhs]); break ; case TY_I16: vm->slots[dst] = (uint16_t )(vm->slots[lhs] + vm->slots[rhs]); break ; case TY_I32: vm->slots[dst] = (uint32_t )(vm->slots[lhs] + vm->slots[rhs]); break ; case TY_I64: vm->slots[dst] = vm->slots[lhs] + vm->slots[rhs]; break ; default : break ; } }
getOrCreateSlot的实现如下,materializeValue为对一些特殊Value的处理,比如像常量值和全局变量
1 2 3 4 5 VM_SLOT Lowerer::getOrCreateSlot (llvm::Value* value) materializeValue (value); return slots.getOrCreateSlot (value); }
其实就是给每个Value对象分配一个递增的索引,如果存在则直接返回。
1 2 3 4 5 6 7 VM_SLOT SlotAllocator::getOrCreateSlot (llvm::Value* v) { auto it = valueToSlot.find (v); if (it != valueToSlot.end ()) return it->second; uint16_t s = nextSlot++; valueToSlot[v] = s; return s; }
对于大多数运算来说,也遵循上面的形式,就不一一赘述了
Alloca、Load、Store指令 仍然以add函数为例,先看对%3这个变量的完整作用过程
1 2 3 %3 = alloca i32, align 4 store i32 %0 , i32* %3 , align 4 %6 = load i32, i32* %3 , align 4
字面上理解是在定义了一个32位大小的变量%3,然后对给%3赋值为0,再从中读取%3的值,真的是这样吗?
假如%3的Slot索引是3,那么slot[3]的值应该是多少呢?没错,答案不是0,因为alloca分配的,应该是是指向一个VM自己分配栈的地址
这里非常需要注意的是,我并没有考虑对齐问题,因为在x86下可以正常运行,但在ARM架构下,如果直接对奇数的地址读写4bytes以上,程序将直接崩溃
1 2 3 4 static inline void vmAlloca (VMState* vm, VM_SLOT dst, VM_SLOT allocaSize) { vm->slots[dst] = (uint64_t )&vm->memory[vm->sp]; vm->sp += allocaSize; }
虽然上面的例子还看不出来问题,我们再来看一个例子,这个adds函数,引用了一个指针,并涉及到取值与存储
1 2 3 4 5 6 7 8 9 10 11 __attribute__((annotate("twogoat_vm" ))) int adds (int * nums, int size) { int res = 0 ; for (int i = 0 ; i < size; i++) { res += nums[i]; nums[i] += 1 ; } return res; }
接下来看看IR中的主要表现
先忽略getelementptr的含义,GEP指令是用来方便取址的,总之%15与%22都是上面例子中nums[i]的地址
可以看到的是接下来进行了%16 = load i32, i32* %15, align 4这样的取值,和store i32 %24, i32* %22, align 4这样的赋值
这和alloca出来的变量的方式是一样的,也就是说alloca后的Value,就应该是一个地址,不然没办法衔接上这里的处理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 11: ; preds = %7 %12 = load i32*, i32** %3, align 8 %13 = load i32, i32* %6, align 4 %14 = sext i32 %13 to i64 %15 = getelementptr inbounds i32, i32* %12, i64 %14 %16 = load i32, i32* %15, align 4 %17 = load i32, i32* %5, align 4 %18 = add nsw i32 %17, %16 store i32 %18, i32* %5, align 4 %19 = load i32*, i32** %3, align 8 %20 = load i32, i32* %6, align 4 %21 = sext i32 %20 to i64 %22 = getelementptr inbounds i32, i32* %19, i64 %21 %23 = load i32, i32* %22, align 4 %24 = add nsw i32 %23, 1 store i32 %24, i32* %22, align 4 br label %25
那么Load和Store的执行方式如下,根据数据类型,直接对指针进行操作即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 static inline void vmLoad (VMState* vm, TYPE_ID ty, VM_SLOT dst, VM_SLOT srcPtrSlot) { uint64_t addr = vm->slots[srcPtrSlot]; switch (ty) { case TY_I8: vm->slots[dst] = *((uint8_t *)addr); break ; case TY_I16: vm->slots[dst] = *((uint16_t *)addr); break ; case TY_I32: vm->slots[dst] = *((uint32_t *)addr); break ; case TY_I64: vm->slots[dst] = *((uint64_t *)addr); break ; case TY_PTR: vm->slots[dst] = *((uint64_t *)addr); break ; default : break ; } } static inline void vmStore (VMState* vm, TYPE_ID ty, VM_SLOT srcSlot, VM_SLOT dstPtrSlot) { uint64_t addr = vm->slots[dstPtrSlot]; switch (ty) { case TY_I8: *((uint8_t *)addr) = (uint8_t )vm->slots[srcSlot]; break ; case TY_I16: *((uint16_t *)addr) = (uint16_t )vm->slots[srcSlot]; break ; case TY_I32: *((uint32_t *)addr) = (uint32_t )vm->slots[srcSlot]; break ; case TY_I64: *((uint64_t *)addr) = (uint64_t )vm->slots[srcSlot]; break ; case TY_PTR: *((uint64_t *)addr) = (uint64_t )vm->slots[srcSlot]; break ; default : break ; } }
LoadConst指令 上面在介绍slot模型中,我们提到Lowerer::materializeValue会用来处理一些特殊的llvm value
下面来看这个例子,也是一个简单的add,但是最后加了114
1 2 3 4 5 6 __attribute__((annotate("twogoat_vm" ))) int add (int a, int b) { int res = a + b + 114 ; return res; }
那在IR中,这个114是如何表示的呢,可以看到这条指令%9 = add nsw i32 %8, 114,也没什么问题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 define dso_local i32 @add(i32 noundef %0 , i32 noundef %1 ) %3 = alloca i32, align 4 %4 = alloca i32, align 4 %5 = alloca i32, align 4 store i32 %0 , i32* %3 , align 4 store i32 %1 , i32* %4 , align 4 %6 = load i32, i32* %3 , align 4 , !dbg !19 %7 = load i32, i32* %4 , align 4 , !dbg !20 %8 = add nsw i32 %6 , %7 , !dbg !21 %9 = add nsw i32 %8 , 114 , !dbg !22 store i32 %9 , i32* %5 , align 4 , !dbg !18 %10 = load i32, i32* %5 , align 4 , !dbg !23 ret i32 %10 , !dbg !24 }
但对于我们的slot模型来说,这是需要额外考虑的地方
114是什么?是一个值,是一个32位的数据,但在llvm中,它仍然是一个llvm::Value对象
如果我们要为了一个常量值,去专门做适配,那么将会非常麻烦,我需要额外考虑lhs是槽索引,rhs是常量;或者lhs是常量,rhs是槽索;引,甚至两者都是常量,整个分发器将会十分臃肿
1 2 3 4 5 6 7 8 9 10 11 12 TYPE_ID ty = read_u8 (&vm); VM_SLOT dst = read_u16 (&vm); VM_SLOT lhs = read_u16 (&vm); VM_SLOT rhs = read_u16 (&vm); switch (instType) { case OP_ADD: vmAdd (&vm, ty, dst, lhs, rhs); break ; case OP_SUB: vmSub (&vm, ty, dst, lhs, rhs); break ; case OP_MUL: vmMul (&vm, ty, dst, lhs, rhs); break ; case OP_SDIV: vmSdiv (&vm, ty, dst, lhs, rhs); break ; case OP_UDIV: vmUdiv (&vm, ty, dst, lhs, rhs); break ; case OP_SREM: vmSrem (&vm, ty, dst, lhs, rhs); break ;
因此我选择的是,在getOrCreateSlot时,就额外添加一条专门的LoadConst指令,上面的函数经过处理后,vm字节码的反汇编结果如下
可以看到在保留了ADD i32 %8 = %7, %9这样的槽索引运算的同时,前面增加了一条LOAD_CONST i32 %9 <- 114指令
1 2 3 4 5 6 7 8 9 10 11 12 13 [00000017] ALLOCA %2 4 [00000022] ALLOCA %3 4 [00000027] ALLOCA %4 4 [00000032] STORE i32 %0 -> %2 [00000038] STORE i32 %1 -> %3 [00000044] LOAD i32 %5 <- %2 [00000050] LOAD i32 %6 <- %3 [00000056] ADD i32 %7 = %5 , %6 [00000064] LOAD_CONST i32 %9 <- 114 [00000072] ADD i32 %8 = %7 , %9 [00000080] STORE i32 %8 -> %4 [00000086] LOAD i32 %10 <- %4 [00000092] RET i32 %10
在VM中是这样运行的
1 2 3 4 5 6 case OP_LOAD_CONST: { TYPE_ID ty = read_u8(&vm); VM_SLOT dst = read_u16(&vm); vmLoadConst(&vm, ty, dst); break ; }
1 2 3 4 5 6 7 8 9 10 static inline void vmLoadConst (VMState* vm, TYPE_ID ty, VM_SLOT dst) { switch (ty) { case TY_I8: vm->slots[dst] = read_u8(vm); break ; case TY_I16: vm->slots[dst] = read_u16(vm); break ; case TY_I32: vm->slots[dst] = read_u32(vm); break ; case TY_I64: vm->slots[dst] = read_u64(vm); break ; case TY_PTR: vm->slots[dst] = read_u64(vm); break ; default : break ; } }
那么一来,核心的slot运算模式没有遭到破坏,而且常量值也能正常Load了
而这就是Lowerer::materializeValue对llvm::ConstantInt的核心处理部分,可以看到正常走了getOrCreateSlot,分配了一个槽
然后再对字节码写入对应的类型和值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 if (llvm::ConstantInt* constant = llvm::dyn_cast <llvm::ConstantInt>(actualValue)) { TYPE_ID ty = TypeConverter::toTYPE_ID (constant->getType ()); VM_SLOT constSlot = slots.getOrCreateSlot (value); writer.emitU8 (OP_LOAD_CONST); writer.emitU8 (ty); writer.emitU16 (constSlot); if (ty == TY_I1) { writer.emitU8 ((uint8_t )constant->getZExtValue ()); } if (ty == TY_I8) { writer.emitU8 ((uint8_t )constant->getZExtValue ()); } else if (ty == TY_I16) { writer.emitU16 ((uint16_t )constant->getZExtValue ()); } else if (ty == TY_I32) { writer.emitU32 ((uint32_t )constant->getZExtValue ()); } else if (ty == TY_I64) { writer.emitU64 ((uint64_t )constant->getZExtValue ()); } llvm::errs () << TypeConverter::typeToString (ty) << " LOAD_CONST_" << TypeConverter::typeToString (ty) << " " << constSlot << " ; \n" ; return ; }
Branch指令
图灵完备是计算机科学术语,指一个系统能模拟单带图灵机并执行所有可计算任务的能力,其概念源于艾伦·图灵于1936年提出的图灵机模型 。
图灵完备不依赖具体硬件形态,而取决于其规则集是否支持条件判断、循环与状态存储等基本计算要素。若某编程语言或虚拟机(如以太坊虚拟机EVM)能实现任意图灵机的行为,即被认为具备图灵完备性 [7]。
图灵不完备的系统则不允许或严格限制循环等结构,这可以保证每段程序都有运行终止的时候(避免死循环),但同时也限制了其功能范围,无法解决所有可计算问题
接下来要实现的就是设计中最重要的一个功能,也是让虚拟机图灵完备的关键一步,分支指令的处理。
仍然从一个简单的例子开始
1 2 3 4 5 6 7 8 9 10 __attribute__((annotate("twogoat_vm" ))) int add (int a, int b) { int res = 0 ; int tmp = a + b; for (int i = 0 ; i < 10 ; i++) { res += tmp; } return res; }
查看IR,这里就是循环体
%13 = icmp slt i32 %12, 10一个ICMP指令,%13即为比较结果True或者False。
然后是br i1 %13, label %14, label %21,如果%13为True则走%14否则走%21
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 br label %11 11 : ; preds = %18 , %2 %12 = load i32, i32* %7 , align 4 %13 = icmp slt i32 %12 , 10 br i1 %13 , label %14 , label %21 14 : ; preds = %11 %15 = load i32, i32* %6 , align 4 %16 = load i32, i32* %5 , align 4 %17 = add nsw i32 %16 , %15 store i32 %17 , i32* %5 , align 4 br label %18 18 : ; preds = %14 %19 = load i32, i32* %7 , align 4 %20 = add nsw i32 %19 , 1 store i32 %20 , i32* %7 , align 4 br label %11 , !llvm.loop !4 21 : ; preds = %11 %22 = load i32, i32* %5 , align 4 ret i32 %22
我们的思路很简单,ICMP指令正常处理就好,本质上和前面的运算指令一样,就是要注意有符号和无符号的处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 static inline void vmIcmp (VMState* vm, TYPE_ID ty, CONDITION_ID cond, VM_SLOT dst, VM_SLOT lhs, VM_SLOT rhs) { uint64_t u_lhs = maskByType(vm->slots[lhs], ty); uint64_t u_rhs = maskByType(vm->slots[rhs], ty); int64_t s_lhs = signExtendByType(u_lhs, ty); int64_t s_rhs = signExtendByType(u_rhs, ty); uint64_t result = 0 ; switch (cond) { case CMP_EQ: result = (u_lhs == u_rhs); break ; case CMP_NE: result = (u_lhs != u_rhs); break ; case CMP_UGT: result = (u_lhs > u_rhs); break ; case CMP_UGE: result = (u_lhs >= u_rhs); break ; case CMP_ULT: result = (u_lhs < u_rhs); break ; case CMP_ULE: result = (u_lhs <= u_rhs); break ; case CMP_SGT: result = (s_lhs > s_rhs); break ; case CMP_SGE: result = (s_lhs >= s_rhs); break ; case CMP_SLT: result = (s_lhs < s_rhs); break ; case CMP_SLE: result = (s_lhs <= s_rhs); break ; default : fprintf (stderr , "[VM] Unknown CMP!\n" ); break ; } vm->slots[dst] = result; }
问题就是跳转指令,比如上面的例子,我们要知道%14或者%23的bytecode偏移,然后设置跳转的地址或者偏移,但问题是在按照指令顺序处理这条BranchInst时,我们根本就不知道后面的bytecode会是如何排布,因此这里就要引入占位。
可以看到在处理BranchInst其实也非常简单,插入类型,用0xDEADBEEF占位
最主要的就是收集当前指令的偏移和需要指向的BasicBlock指针,放入unresolvedBranches,等函数的所有bytecode预生成完后,再统一对改vector里的元素进行处理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 bool Lowerer::lowerBranch (llvm::BranchInst& BR) if (BR.isUnconditional ()) { llvm::BasicBlock *targetBlock = BR.getSuccessor (0 ); writer.emitU8 (OP_BR); unresolvedBranches.push_back ({writer.getCurrentOffset (), targetBlock}); writer.emitU32 (0xDEADBEEF ); } else { llvm::Value* condVal = BR.getCondition (); llvm::BasicBlock* trueBB = BR.getSuccessor (0 ); llvm::BasicBlock* falseBB = BR.getSuccessor (1 ); VM_SLOT condSlot = getOrCreateSlot (condVal); writer.emitU8 (OP_BR_COND); writer.emitU16 (condSlot); unresolvedBranches.push_back ({writer.getCurrentOffset (), trueBB}); writer.emitU32 (0xDEADBEEF ); unresolvedBranches.push_back ({writer.getCurrentOffset (), falseBB}); writer.emitU32 (0xCAFEBABE ); } return true ; }
这里就是翻译IR的入口,可以看到在每个BasicBlock进行处理前,就已经记录下了对应的bytecode偏移至bbToOffset
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 bool Lowerer::run () lowerArgsAndSignature (); for (auto & BB : F) { bbToOffset[&BB] = writer.getCurrentOffset (); for (auto & I : BB) { llvm::errs () << I << " ; " ; lowerInstruction (I); llvm::errs () << "\n" ; } } doBackpatching (); writer.patchMemoryMaxSize (memoryMaxSize); writer.patchDataSegmentCount (slots.getSlotCount ()); return true ; }
接下来就是遍历unresolvedBranches,并patch对应偏移的bytecode,最终实现循环分支的处理
1 2 3 4 5 6 7 8 9 10 void Lowerer::doBackpatching () for (auto & debt : unresolvedBranches) { uint32_t patchOffset = debt.first; llvm::BasicBlock* targetBB = debt.second; uint32_t realOffset = bbToOffset[targetBB]; writer.patchU32 (patchOffset, realOffset); } }
虚拟机最终生成出来的指令如下,可以看到准确无误地还原了分支。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 [00000 108] BR pc -> 113 [00000113] LOAD i32 %11 <- %6 [00000119] LOAD_CONST i32 %13 <- 10 [00000127] ICMP slt i32 %12 = %11 , %13 [00000136] BR_COND %12 ? 147 : 211 ; if slots[12 ] == 1 then pc = 147 else pc = 211 [00000147] LOAD i32 %14 <- %5 [00000153] LOAD i32 %15 <- %4 [00000159] ADD i32 %16 = %15 , %14 [00000167] STORE i32 %16 -> %4 [00000173] BR pc -> 178 [00000178] LOAD i32 %17 <- %6 [00000184] LOAD_CONST i32 %19 <- 1 [00000192] ADD i32 %18 = %17 , %19 [00000200] STORE i32 %18 -> %6 [00000206] BR pc -> 113 [00000211] LOAD i32 %20 <- %4 [00000217] RET i32 %20
接下来vm层的处理也非常简单,当然我这里直接用的是地址赋值而非偏移
1 2 3 4 5 6 7 8 9 10 11 static inline void vmBr (VMState* vm, uint32_t off) { vm->pc = off; } static inline void vmBrCond (VMState* vm, VM_SLOT resSlot, uint32_t tOff, uint32_t fOff) { if (vm->slots[resSlot] == 1 ) { vm->pc = tOff; } else { vm->pc = fOff; } }
全局变量/符号引用 接下来可以说是真正遇到了一个大难点,要处理全局变量和符号引用
依旧先从一个简单的例子看起
1 2 3 4 5 6 7 8 9 10 int len = 5 ;unsigned char key[] = "hello" ;unsigned char tmp[5 ];__attribute__((annotate("twogoat_vm" ))) void mov_test (uint8_t *input) { for (int i = 0 ; i < len; i++) { input[i] = key[i]; } }
接下来查看IR,其实总体上跟之前的没有任何差别,但问题就在@len和@key上
我们要传入@len或者@key的在内存中的虚拟地址,才能正常在VM中完成load和store等操作,这也是我设计的要遵守的规范,肯定要像之前处理Const一样,额外添加处理的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 @len = dso_local global i32 5 , align 4 @key = dso_local global [6 x i8] c"hello\00" , align 1 ; Function Attrs: noinline nounwind optnone uwtable define dso_local void @xor_test(i8* noundef %0 ) %2 = alloca i8*, align 8 %3 = alloca i32, align 4 store i8* %0 , i8** %2 , align 8 store i32 0 , i32* %3 , align 4 br label %4 4 : ; preds = %17 , %1 %5 = load i32, i32* %3 , align 4 %6 = load i32, i32* @len , align 4 %7 = icmp slt i32 %5 , %6 br i1 %7 , label %8 , label %20 8 : ; preds = %4 %9 = load i32, i32* %3 , align 4 %10 = sext i32 %9 to i64 %11 = getelementptr inbounds [6 x i8], [6 x i8]* @key, i64 0 , i64 %10 %12 = load i8, i8* %11 , align 1 %13 = load i8*, i8** %2 , align 8 %14 = load i32, i32* %3 , align 4 %15 = sext i32 %14 to i64 %16 = getelementptr inbounds i8, i8* %13 , i64 %15 store i8 %12 , i8* %16 , align 1 br label %17 17 : ; preds = %8 %18 = load i32, i32* %3 , align 4 %19 = add nsw i32 %18 , 1 store i32 %19 , i32* %3 , align 4 br label %4 , !llvm.loop !4 20 : ; preds = %4 ret void }
我的想法是,添加一个Module Pass,在程序进行处理之前,就先收集好全局变量,函数等信息,并建立一个符号指针表
可以看到先收集了当前Module下的所有Function地址,再收集了globals的地址,当然这里也要十分注意的是,拥有llvm保留字段的对象必须要跳过,否则链接时会提示找不到符号信息
通过ConstantArray::get,能够直接将带有llvm::Value对象的Vector转化为llvm的ConstantArray,然后再转化为全局变量即可,接下来就可以拿到符号表了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 void runOnInitGlobalSymble (Module& M) LLVMContext& ctx = M.getContext (); errs () << "[Functions]\n" ; for (Function &F : M) { if (F.getName ().startswith ("llvm" )) { continue ; } errs () << " - " << F.getName (); if (F.isDeclaration ()) { errs () << " (External Declaration)" ; } errs () << "\n" ; symbolPtrs.push_back (&F); } errs () << "\n[Global Variables]\n" ; for (GlobalVariable &GV : M.globals ()) { if (GV.getName ().startswith ("llvm" ) || GV.getName () == ".twogoat_globalSymbolTable" ) { continue ; } if (GV.hasSection () && GV.getSection () == "llvm.metadata" ) { errs () << "[skip metadata global] " << GV.getName () << "\n" ; continue ; } errs () << " - " << GV.getName () << " (Type: " ; GV.getType ()->print (errs ()); errs () << ")\n" ; symbolPtrs.push_back (&GV); } errs () << "-------------------------------------------------\n\n" ; for (int i = 0 ; i < symbolPtrs.size (); i++) { toSymbolId[symbolPtrs[i]] = i; } ArrayType* arrayType = ArrayType::get (PointerType::getUnqual (ctx), symbolPtrs.size ()); Constant* data = ConstantArray::get (arrayType, symbolPtrs); globalSymbolTable = new GlobalVariable (M, data->getType (), true , GlobalVariable::ExternalLinkage, data, ".twogoat_globalSymbolTable" ); }
接下来就是非常重要的一步,需要将这个函数表导出给VM框架使用
创建一个名为getglobalSymbolTable的函数,设置属性为ExternalLinkage,其最主要的作用就是返回globalSymbolTable的地址
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 bool FunctionWriter::createGetglobalSymbolTableFuction (llvm::Module& M, llvm::GlobalVariable* globalSymbolTable) llvm::LLVMContext& ctx = M.getContext (); llvm::FunctionType* funcType = llvm::FunctionType::get (llvm::PointerType::getUnqual (ctx), false ); llvm::Function* F = M.getFunction ("getglobalSymbolTable" ); if (!F) { F = llvm::Function::Create (funcType, llvm::GlobalVariable::ExternalLinkage, "getglobalSymbolTable" , M); } llvm::BasicBlock* entryBlock = llvm::BasicBlock::Create (ctx, "getglobalSymbolTable_entry" , F); llvm::Type* retType = F->getReturnType (); llvm::Constant* globalSymbolTablePtr = llvm::ConstantExpr::getBitCast (globalSymbolTable, retType); llvm::IRBuilder<> builder (entryBlock); builder.CreateRet (globalSymbolTablePtr); return true ; }
在VM中设置为extern,然后链接时就会自动找到了
1 2 extern void * getglobalSymbolTable (void ) ;vm->symbolTable = (uintptr_t *)getglobalSymbolTable();
需要加载符号时,直接从symbolTable中取出对应索引的地址即可
1 2 3 static inline void vmLoadSymbolAddress (VMState* vm, TYPE_ID ty, VM_SLOT dst, uint16_t symbolIdx) { vm->slots[dst] = vm->symbolTable[symbolIdx]; }
那么和LoadConst一样,添加一个LoadSymbol的特殊处理,在字节码中插入该符号在符号地址表中的索引
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 if (llvm::GlobalValue* GV = llvm::dyn_cast <llvm::GlobalValue>(actualValue)) { auto it = toSymbolId.find (GV); if (it == toSymbolId.end ()) { llvm::errs () << "[VM Error] Global symbol not registered: " << GV->getName () << "\n" ; return ; } VM_SLOT dstSlot = slots.getOrCreateSlot (value); writer.emitU8 (OP_LOAD_SYMBOL_ADDR); writer.emitU8 (TY_PTR); writer.emitU16 (dstSlot); writer.emitU16 (it->second); llvm::errs () << "ptr LOAD_SYMBOL_ADDR " << dstSlot << " @" << GV->getName () << " (id=" << it->second << ") ; \n" ; return ; }
在VM的反汇编中,可以看到是通过LOAD_SYM ptr %6 <- sym[3],去加载符号地址的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 [00000016] ALLOCA %1 8 [00000021] ALLOCA %2 4 [00000026] STORE ptr %0 -> %1 [00000032] LOAD_CONST i32 %3 <- 0 [00000040] STORE i32 %3 -> %2 [00000046] BR pc -> 51 [00000051] LOAD i32 %4 <- %2 [00000057] LOAD_SYM ptr %6 <- sym[3 ] [00000063] LOAD i32 %5 <- %6 [00000069] ICMP slt i32 %7 = %4 , %5 [00000078] BR_COND %7 ? 89 : 219 ; if slots[7 ] == 1 then pc = 89 else pc = 219 [00000089] LOAD i32 %8 <- %2 [00000095] SEXT i32 -> i64 %9 <- %8 [00000 102] LOAD_SYM ptr %11 <- sym[4 ] [00000 108] LOAD_CONST i64 %12 <- 0 [00000120] GEP %10 = %11 + (%12 * 6 ) + (%9 * 1 ) [00000138] LOAD i8 %13 <- %10 [00000144] LOAD ptr %14 <- %1 [00000150] LOAD i32 %15 <- %2 [00000156] SEXT i32 -> i64 %16 <- %15 [00000163] GEP %17 = %14 + (%16 * 1 ) [00000175] STORE i8 %13 -> %17 [00000181] BR pc -> 186 [00000186] LOAD i32 %18 <- %2 [00000192] LOAD_CONST i32 %20 <- 1 [00000200] ADD i32 %19 = %18 , %20 [00000208] STORE i32 %19 -> %2 [00000214] BR pc -> 51 [00000219] EXIT
编译好后在ida中打开,可以看到symbolTable存放了各种符号的地址,那就没问题了
函数调用处理 Call指令的问题 接下来的部分,是我在整个编写中遇到的最困难一步,简单来说就是“把一个参数数组动态传递给函数并进行调用”的问题
依旧先看一个简单的call的例子
1 2 3 4 5 6 7 8 9 10 11 12 __attribute__((annotate("twogoat_vm" ))) int add (int a, int b) { return a + b; } __attribute__((annotate("twogoat_vm" ))) int call_test (int a, int b) { printf ("%d %d \n" , a, b); int c = a + 1 ; int d = b + 1 ; return add(c, d); }
IR如下。可以看到从结构上其实也没有太大变化,通过解析CallInst,我们能拿到FunctionType,通过getArgOperand拿到参数对象,那么直接塞入字节码就行了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 define dso_local i32 @add(i32 noundef %0 , i32 noundef %1 ) %3 = alloca i32, align 4 %4 = alloca i32, align 4 store i32 %0 , i32* %3 , align 4 store i32 %1 , i32* %4 , align 4 %5 = load i32, i32* %3 , align 4 %6 = load i32, i32* %4 , align 4 %7 = add nsw i32 %5 , %6 ret i32 %7 } ; Function Attrs: noinline nounwind optnone uwtable define dso_local i32 @call_test(i32 noundef %0 , i32 noundef %1 ) %3 = alloca i32, align 4 %4 = alloca i32, align 4 %5 = alloca i32, align 4 %6 = alloca i32, align 4 store i32 %0 , i32* %3 , align 4 store i32 %1 , i32* %4 , align 4 %7 = load i32, i32* %3 , align 4 %8 = add nsw i32 %7 , 1 store i32 %8 , i32* %5 , align 4 %9 = load i32, i32* %4 , align 4 %10 = add nsw i32 %9 , 1 store i32 %10 , i32* %6 , align 4 %11 = load i32, i32* %5 , align 4 %12 = load i32, i32* %6 , align 4 %13 = call i32 @add(i32 noundef %11 , i32 noundef %12 ) ret i32 %13 }
假如遇到变参函数,像printf怎么办,举一个最简单的例子
1 2 3 4 5 6 __attribute__((annotate("twogoat_vm" ))) void call_test (int a, int b) { printf ("%d \n" , a); printf ("%d %d \n" , a, b); return ; }
llvm IR如下,忽略掉前面那一串gep指令,能看的出每一条call printf指令传参其实已经确定好了
1 2 3 4 5 6 7 8 9 10 11 12 define dso_local void @call_test(i32 noundef %0 , i32 noundef %1 ) #0 { %3 = alloca i32, align 4 %4 = alloca i32, align 4 store i32 %0 , i32* %3 , align 4 store i32 %1 , i32* %4 , align 4 %5 = load i32, i32* %3 , align 4 %6 = call i32 (i8*, ...) @printf (i8* noundef getelementptr inbounds ([5 x i8], [5 x i8]* @.str, i64 0 , i64 0 ), i32 noundef %5 ) %7 = load i32, i32* %3 , align 4 %8 = load i32, i32* %4 , align 4 %9 = call i32 (i8*, ...) @printf (i8* noundef getelementptr inbounds ([8 x i8], [8 x i8]* @.str.1 , i64 0 , i64 0 ), i32 noundef %7 , i32 noundef %8 ) ret void }
真正的挑战在于物理机的调用约定(Native ABI)。
比如上面的add函数,经过保护后,他仍需要保持一个int add(int a1, int a2)的形式
1 2 3 4 RETURN_VALUE __fastcall add(unsigned int a1, unsigned int a2) { return vmEntry(&bytecode1, a1, a2); }
我的 VM 设计原则是不破坏被保护函数的 ABI。在 VM 内部,所有的数据类型都被擦除,统一成了 uint64_t 的 Slot 数组。但是,当真实的 CPU 执行 add(1, 2) 时,它需要将参数精确地放入特定的寄存器(如 RDI, RSI)。VM 在运行时是一堆无法感知底层寄存器的 C 代码,不可能动态地去构建形如 (int (*)(int, int))pAdd(1, 2) 的强类型调用。
起初,我考虑过引入 libffi 库来动态处理 ABI,但这会导致整个 VMP 项目变得极其臃肿,偏离了轻量级的初衷。
类型降维与 LLVM 动态分发 仔细剖析后,我意识到这里其实交织着三个维度的状态转换:
源程序维度(IR):拥有严格的类型系统(i32, i8*, 变参等)。
虚拟机维度(VM Runtime):类型完全擦除,全是 uint64_t 的 Slot。
物理机维度(Native ABI):严格遵循底层寄存器/栈传参约定。
既然 VM 在运行时无法感知类型,那我们就在编译期(LLVM Pass)利用编译器自身的后端能力,提前把不同类型的调用路线铺好。
核心思路是:函数签名收集 + 动态生成分发器 (vmCall)。
最后效果如下,这是从AES加密的项目中截取的vmCall伪代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 __int64 __fastcall vmCall (__int16 a1, void (__fastcall *a2)(_QWORD, _QWORD), _QWORD *a3) { __int64 v4; v4 = 0 ; switch ( a1 ) { case 0 : a2(*a3, a3[1 ]); break ; case 1 : case 5 : case 6 : ((void (__fastcall *)(_QWORD, _QWORD, _QWORD))a2)(*a3, a3[1 ], a3[2 ]); break ; case 2 : ((void (__fastcall *)(_QWORD))a2)(*a3); break ; case 3 : v4 = ((unsigned __int8 (__fastcall *)(_QWORD, _QWORD))a2)(*a3, a3[1 ]); break ; case 4 : v4 = ((unsigned int (__fastcall *)(_QWORD))a2)(*a3); break ; case 7 : v4 = ((unsigned int (__fastcall *)(_QWORD, _QWORD, _QWORD))a2)(*a3, a3[1 ], a3[2 ]); break ; case 8 : case 9 : v4 = ((unsigned int (__fastcall *)(_QWORD, _QWORD))a2)(*a3, a3[1 ]); break ; default : return v4; } return v4; }
lower中的核心处理如下
注意funcTy只是用来获取返回值类型的,考虑到可变参数,函数签名还需要用getArgOperand来获取
当遍历 IR 遇到 CallInst 时,我们提取出它的返回值类型和参数类型,合成一个独一无二的 Signature ID。即便是 printf 这样的变参函数,每一次调用的实际参数类型在 IR 中也是确定的,因此会自动分配不同的 ID。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 llvm::FunctionType *funcTy = I.getFunctionType (); std::vector<TYPE_ID> callSignature; callSignature.push_back (TypeConverter::toTYPE_ID (funcTy->getReturnType ())); for (int i = 0 ; i < I.arg_size (); ++i) { callSignature.push_back (TypeConverter::toTYPE_ID (I.getArgOperand (i)->getType ())); } uint16_t callSignatureId = calls.getOrCreateCallSignatureID (callSignature); llvm::Value* callee = I.getCalledOperand (); VM_SLOT calleeSlot = getOrCreateSlot (callee); std::vector<VM_SLOT> argSlots; for (unsigned i = 0 ; i < I.arg_size (); ++i) { argSlots.push_back (getOrCreateSlot (I.getArgOperand (i))); } llvm::errs () << "Call " ; llvm::errs () << callSignatureId << " ; " ; writer.emitU8 (OP_CALL); writer.emitU16 (calleeSlot); writer.emitU16 (callSignatureId); writer.emitU8 (argSlots.size ()); for (VM_SLOT slot : argSlots) { writer.emitU16 (slot); } if (!funcTy->getReturnType ()->isVoidTy ()) { writer.emitU8 (0 ); VM_SLOT retSlot = slots.getOrCreateSlot (&I); writer.emitU16 (retSlot); llvm::errs () << "Call result -> %" << retSlot << "\n" ; } else { writer.emitU8 (1 ); } llvm::errs () << "\n" ;
接下来就是最关键的一步,利用 IR Builder 动态构建 FFI 桥接器。
通过收集到的函数签名信息,去生成vmCall,对于收集到的每一个签名,生成一个 case 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 void FunctionWriter::createVmCallFunction (llvm::Module& M, callSignatureAllocator& calls) llvm::LLVMContext& ctx = M.getContext (); std::vector<llvm::Type*> argsType = {llvm::Type::getInt16Ty (ctx), llvm::Type::getInt8PtrTy (ctx), llvm::Type::getInt64PtrTy (ctx)}; llvm::FunctionType* vmCallType = llvm::FunctionType::get (llvm::Type::getInt64Ty (ctx), argsType, false ); llvm::Function* vmCallFunction = llvm::Function::Create (vmCallType, llvm::Function::ExternalLinkage, "vmCall" , M); llvm::BasicBlock* switchBlock = llvm::BasicBlock::Create (ctx, "vmCallSwitchBlock" , vmCallFunction); llvm::IRBuilder<> builder (switchBlock); llvm::AllocaInst* resultAlloca = builder.CreateAlloca (builder.getInt64Ty (), nullptr , "resultAlloca" ); builder.CreateStore (builder.getInt64 (0 ), resultAlloca); llvm::BasicBlock* retBlock = llvm::BasicBlock::Create (ctx, "vmCallRetBlock" , vmCallFunction); llvm::IRBuilder<> retBuilder (retBlock); llvm::Value* returnVal = retBuilder.CreateLoad (retBuilder.getInt64Ty (), resultAlloca); retBuilder.CreateRet (returnVal); llvm::Value* callSignatureId = vmCallFunction->getArg (0 ); llvm::Value* callFunctionPtr = vmCallFunction->getArg (1 ); llvm::Value* callArgsPtr = vmCallFunction->getArg (2 ); const std::vector<std::vector<TYPE_ID>>& callSignatureArray = calls.getsignatureArray (); llvm::SwitchInst* switchInst = builder.CreateSwitch (callSignatureId, retBlock, calls.getCallSignatureCount ()); for (auto callSignature: callSignatureArray) { uint16_t signatureID = calls.getOrCreateCallSignatureID (callSignature); llvm::BasicBlock* callBlock = llvm::BasicBlock::Create (ctx, "callBlock_" , vmCallFunction); switchInst->addCase (builder.getInt16 (signatureID), callBlock); llvm::IRBuilder<> callBD (callBlock); llvm::Type* returnType = TypeConverter::toLLVM_Type (callSignature[0 ], ctx); std::vector<llvm::Type*> callArgsType; std::vector<llvm::Value*> argsArray; for (int i = 1 ; i < callSignature.size (); i++) { llvm::Type* argType = TypeConverter::toLLVM_Type (callSignature[i], ctx); callArgsType.push_back (argType); llvm::Value* idxVal = callBD.getInt32 (i - 1 ); llvm::Value* argPtr = callBD.CreateGEP (callBD.getInt64Ty (), callArgsPtr, idxVal); llvm::Value* argValue = callBD.CreateLoad (callBD.getInt64Ty (), argPtr); llvm::Value* realArgValue = argValue; if (argType->isIntegerTy () && argType->getIntegerBitWidth () < 64 ) { realArgValue = callBD.CreateTrunc (argValue, argType); } else if (argType->isPointerTy ()) { realArgValue = callBD.CreateIntToPtr (argValue, argType); } else if (argType->isFloatTy () || argType->isDoubleTy ()) { realArgValue = callBD.CreateBitCast (argValue, argType); } argsArray.push_back (realArgValue); } llvm::FunctionType* callFunctionType = llvm::FunctionType::get (returnType, callArgsType, false ); llvm::PointerType* funcPtrType = llvm::PointerType::getUnqual (callFunctionType); llvm::Value* castedFuncPtr = callBD.CreateBitCast (callFunctionPtr, funcPtrType); llvm::CallInst* callResult = callBD.CreateCall (callFunctionType, castedFuncPtr, argsArray); if (!returnType->isVoidTy ()) { llvm::Value* ret64 = callResult; if (returnType->isIntegerTy () && returnType->getIntegerBitWidth () < 64 ) { ret64 = callBD.CreateZExt (callResult, callBD.getInt64Ty ()); } else if (returnType->isPointerTy ()) { ret64 = callBD.CreatePtrToInt (callResult, callBD.getInt64Ty ()); } callBD.CreateStore (ret64, resultAlloca); } callBD.CreateBr (retBlock); } }
当 VMP 编译出的程序真正运行时,VM 内部处理 OP_CALL 的逻辑变得异常清爽。VM 只需要将零散的 Slot 收集成数组,直接丢给编译期生成的 vmCall 即可:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 case OP_CALL: { VM_SLOT callee = read_u16(&vm); uint16_t calleeId = read_u16(&vm); uint8_t slotsSize = read_u8(&vm); uint64_t * slotsPtr = (uint64_t *)malloc (sizeof (uint64_t ) * slotsSize); for (int i = 0 ; i < slotsSize; i++) { slotsPtr[i] = vm.slots[read_u16(&vm)]; } uint64_t result = vmCall(calleeId, (void *)vm.slots[callee], slotsPtr); uint8_t isVoid = read_u8(&vm); if (isVoid == 0 ) { VM_SLOT retSlot = read_u16(&vm); vm.slots[retSlot] = result; } free (slotsPtr); break ; }
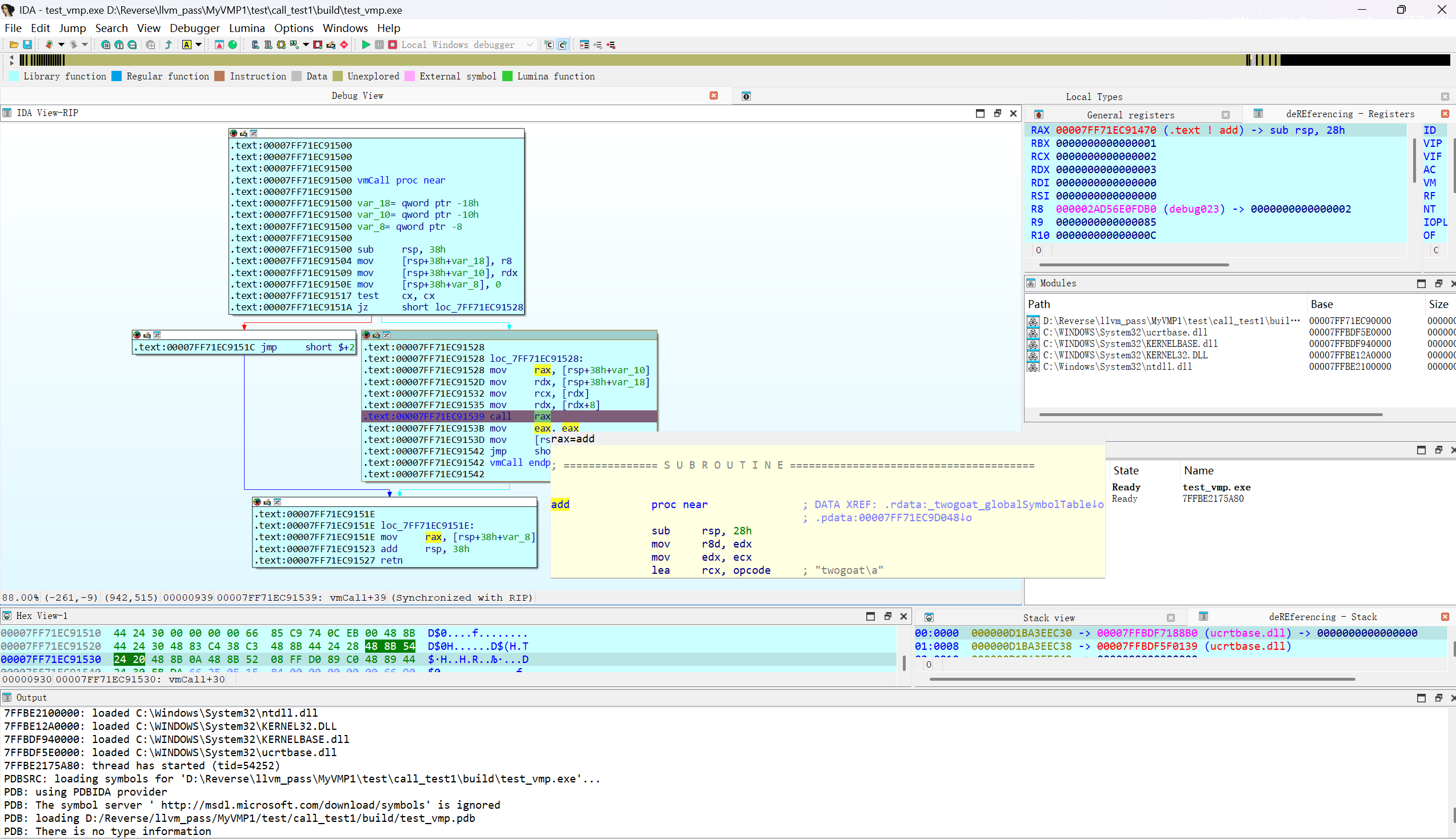
执行的最终效果,可以看到,通过vmCall成功调用了add函数,并且完全遵守ABI
思考 经过此次的实践,我一直在思考一个问题,为什么我用C语言想要实现上面这样一个“把一个参数数组动态传递给函数”的功能会如此困难,如果是别的语言,到底可以如何实现。
弱类型/动态语言的降维打击 在询问AI后,我得知了在 JS 这种运行在庞大虚拟机(V8)上的弱类型动态语言中,类型是在运行时绑定的。不需要手动处理参数解包,也不用管寄存器,一切都可以用“展开语法”瞬间完,开发者只需写出如下代码即可实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 let vmSlots = [10 , 20 ]; function executeOpCall (calleeFunc, slotsArgs ) { let result = calleeFunc (...slotsArgs); return result; } function add (a, b ) { return a + b; }let ret = executeOpCall (add, vmSlots);
带元数据的强类型/静态语言:运行时反射 如果在其他严格区分类型的高级语言(如 Java, C#, Go)中,不使用 LLVM 动态生成代码,它们是如何实现的呢?反射(Reflection)。
C# / Java (拥有运行时反射的强类型语言),这类语言虽然是强类型的,但它们在运行时保留了完整的元数据(Metadata)。你可以直接利用语言自带的反射机制动态调用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 using System;using System.Reflection;public class VM { public static int Add (int a, int breturn a + b; } public static object ExecuteOpCall (MethodInfo callee, object [] vmSlots ) object result = callee.Invoke(null , vmSlots); return result; } public static void Main () object [] slots = new object [] { 10 , 20 }; MethodInfo method = typeof (VM).GetMethod("Add" ); object ret = ExecuteOpCall(method, slots); } }
Go 是编译为机器码的,它没有庞大的虚拟机,但保留了反射能力。处理逻辑与 C# 类似,但类型要求更加严格。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 package mainimport "reflect" func vmCall (callee any, slotsArgs []any) f := reflect.ValueOf(callee) in := make ([]reflect.Value, len (slotsArgs)) for i, arg := range slotsArgs { in[i] = reflect.ValueOf(arg) } out := f.Call(in) if len (out) > 0 { return out[0 ].Interface() } return nil } func add (a int , b int ) int { return a + b }func main () slots := []any{10 , 20 } result := vmCall(add, slots) }
动态语言与静态语言 这里又涉及到了一个新概念,比如对上面的add函数而言,在编译为二进制文件后,程序在运行时,只通过Program Headers映射到内存,对它而言,它不知道运行时”add”这个字符串对应哪个函数,更不知道它的参数类型,返回值类型等。
但对于强类型且带有反射的语言(如 C#, Java, Go),编译器最终还会额外生成一份名为元数据(Metadata)的资源。
Metadata里清楚地记录着程序里有哪些类,类的名字,类有哪些方法,方法名,参数类型等
因此完全可以写出如下的代码,这就是运行时通过Metadata解析到的信息
1 2 3 4 5 6 7 8 9 10 MethodInfo method = typeof (MyClass).GetMethod("add" ); ParameterInfo[] params = method.GetParameters(); Console.WriteLine(params [0 ].ParameterType); object [] args = new object [] { 10 , 20 };method.Invoke(null , args );
对于js来说,它同样具有这样的能力,但这就要说到动态语言与静态语言的区别
在像C/C++/Java的静态语言里,一个重要特性就是编译期与运行期的隔离。因此在运行时想要获取编译时的元数据,就要通过反射(Reflection)。
但对于像js这样的动态语言,它是JIT编译的动态脚本语言,它本身就没有什么编译与运行的隔离,概念上这更偏向于内省(Introspection)
比如在 C# 中,需要用 typeof(MyClass).GetMethod(“add”) 这种极其繁琐的反射 API 去找方法。
1 2 3 4 5 let obj = { add : function (a, b ) { return a + b; } };obj.add (1 , 2 ); obj["add" ](1 , 2 );
同时,函数本身就是一个普通对象,apply 和 call 只是自带的方法,而非什么沉重的反射 API。
总结 回顾我的 VMP 开发历程,之所以在处理 Native Call 时感到极度痛苦,根本原因在于 C/C++ 为了极致的性能和底层控制,剥离了任何动态和内省能力。
在这个密不透风的纯静态环境里,无法像 JS 那样直接展开参数,也无法像 C# 那样通过 Metadata 动态拆箱。因此,我只能且必须利用 LLVM Pass,在编译期提前洞悉所有的类型信息,并把所有需要的状态转移路线硬编码成一个巨大的 vmCall 分发器,本质上还是编译时动态而运行时静态的方案。
函数入口替换 接下来就是整个保护流程的最后一步了,将原函数内容全部删除,修改为VM入口
其实流程就是生成bytecode全局变量,通过F.deleteBody()删除原函数,然后再原参数列表添加字节码的地址,再进行vmEntry的调用
比如int add(int a, int b),最后函数体即为vmEntry(&addBytecode, a, b);
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 void FunctionWriter::rewriteToVMStub (llvm::Function& F, const std::vector<uint8_t >& bytecode) llvm::LLVMContext& ctx = F.getContext (); llvm::Module* M = F.getParent (); llvm::Constant* initData = llvm::ConstantDataArray::get (ctx, bytecode); llvm::GlobalVariable* globalBytecode = new llvm::GlobalVariable ( *M, initData->getType (), true , llvm::GlobalVariable::InternalLinkage, initData, F.getName () + "_bytecode" ); F.deleteBody (); llvm::BasicBlock* vmEntryBB = llvm::BasicBlock::Create (ctx, "vmEntryBB" , &F); llvm::IRBuilder <>builder (vmEntryBB); std::vector<llvm::Type*> argsTypes; argsTypes.push_back (builder.getInt8PtrTy ()); int argSize = F.arg_size (); for (int i = 0 ; i < argSize; i++) { argsTypes.push_back (F.getArg (i)->getType ()); } llvm::FunctionType *vmEntryFuncType = llvm::FunctionType::get (F.getReturnType (), argsTypes, false ); llvm::FunctionCallee vmEntryFunc = M->getOrInsertFunction ("vmEntry" , vmEntryFuncType); std::vector<llvm::Value*> argsArray; llvm::Value *bytecodePtr = builder.CreateBitCast (globalBytecode, llvm::Type::getInt8PtrTy (ctx)); argsArray.push_back (bytecodePtr); for (int i = 0 ; i < argSize; i++) { argsArray.push_back (F.getArg (i)); } llvm::Value* retVal = builder.CreateCall (vmEntryFunc, argsArray); if (F.getReturnType () == builder.getVoidTy ()) { builder.CreateRetVoid (); } else { builder.CreateRet (retVal); } }
GEP指令处理 gep指令,也就是GetElementPtrInst,可以说是我到最后也没有搞太明白的一个地方
这里就简单列出两种我在实际生成IR后看见的GEP指令形态,就知道为什么它和别的指令处理与众不同了
1 2 3 4 5 // 形态 A:带有连续多个索引,比如开头多了一个 0 %24 = getelementptr inbounds [256 x i8], [256 x i8]* %2, i64 0, i64 %23 // 形态 B:只有一个简单的索引 %15 = getelementptr inbounds i32, i32* %12, i64 %14
为什么形态 A 必须要跟着一个 i64 0?深入查阅资料后我才明白,这是 LLVM 类型系统的“剥洋葱”机制。形态 A 中的 %2 是一个指向数组的指针([256 x i8]*),第一个 0 的作用是在指针本身的跨度上偏移 0,实际上是为了“解引用”进入数组内部;而第二个 %23 才是真正在数组元素之间的偏移。
那如果形态A没有第一个i64 0,会怎么样呢,那就是指向跳到 %23 个[256 x i8] 数组对象的地址
理解起来非常抽象,看看VM对应handle的实现
1 2 3 4 5 6 7 8 9 10 11 12 static inline void vmGepStrict (VMState* vm, VM_SLOT dst, VM_SLOT baseSlot, uint8_t numIndices) { uint64_t currentAddr = vm->slots[baseSlot]; for (uint8_t i = 0 ; i < numIndices; i++) { VM_SLOT idxSlot = read_u16(vm); uint32_t stride = read_u32(vm); int64_t idxVal = (int64_t )vm->slots[idxSlot]; currentAddr += (idxVal * stride); } vm->slots[dst] = currentAddr; }
bytecode要如何计算这个步长呢,可以看到需要通过DataLayout去进行拆解,整个过程还是比较复杂的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 bool Lowerer::lowerGEP (llvm::GetElementPtrInst& I) VM_SLOT dstSlot = getOrCreateSlot (&I); VM_SLOT baseSlot = getOrCreateSlot (I.getPointerOperand ()); std::vector<uint16_t > indexSlots; for (unsigned i = 1 ; i < I.getNumOperands (); ++i) { indexSlots.push_back (getOrCreateSlot (I.getOperand (i))); } writer.emitU8 (OP_GEP); writer.emitU16 (dstSlot); writer.emitU16 (baseSlot); writer.emitU8 (static_cast <uint8_t >(indexSlots.size ())); const llvm::DataLayout &DL = I.getModule ()->getDataLayout (); auto it = llvm::gep_type_begin (I); for (unsigned i = 0 ; i < indexSlots.size (); ++i, ++it) { uint32_t stride = 0 ; if (auto * structTy = it.getStructTypeOrNull ()) { uint64_t fieldIdx = llvm::cast <llvm::ConstantInt>(I.getOperand (i + 1 ))->getZExtValue (); stride = static_cast <uint32_t >(DL.getStructLayout (structTy)->getElementOffset (fieldIdx)); } else { stride = static_cast <uint32_t >(DL.getTypeAllocSize (it.getIndexedType ())); } writer.emitU16 (indexSlots[i]); writer.emitU32 (stride); } return true ; }
写在最后 还有一些细枝末节的问题就不在这里过多讨论了,比如像类型转换,位拓展这些。总而言之,整个项目写下来,真的十分耗费精力,特别是处理函数调用和GEP指令的时候,因为也不熟悉更高级的LLVM语法,和对编译时运行时这些概念模糊不清,几经想放弃,好在在AI的帮助下,最终也是顺利完成了工作。
在看到复杂的AES的能通过一个编译选项,直接由我自己的vmp框架保护时,成就感也是满满。